Latent Physionotrace
Mechanical Installation, Generative AI Algorithms, Real-Time Animation, Mixed Media
Dimensions Variable
2025
潛像描繪儀
機械裝置、機器繪圖、演算法、生成動畫、複合媒材
依場地而定
2025
︎ Magic Noise: How AI Wanders in the Latent Space, LIN & LIN Gallery
︎ 神奇的雜訊:AI的潛在漫步方式,大未來林舍畫廊
![]()
展場入口處為《潛像描繪儀》畫出的肖像畫
In recent years, the Diffusion Model has become the state of the art (SOTA) in image generation systems. It improves upon earlier “one-step” generative methods by dividing the process into a series of smaller steps. At each step, instead of directly using the model’s computed output, the algorithm randomly selects a nearby result within a certain range. Both experimental data and visual outcomes demonstrate that this modification has brought about a major breakthrough. A similar design principle is also found in large language models.
The generated output exists as a vector in latent space—essentially, a coordinate. Randomly selecting another coordinate nearby corresponds to diffusing outward from the original point with a Gaussian probability distribution: the closer a point is, the higher its probability; the farther it is, the lower. This process, known as adding noise, gives the diffusion model its name.
In visualizations of models like Stable Diffusion or Midjourney, the process is often represented as “denoising.” However, the true logic that allows AI to approach something resembling creativity lies precisely in the step of adding noise. This is the main reason—and necessity—behind why generative AI produces different results each time. One can imagine this process as AI taking a wandering exploration through latent space, step by step, during its generative journey.
This work consists of three installations: a Galton board, an AI image generation algorithm, and a Physionotrace.
近幾年成為影像生成模型SOTA(State of The Art,意指某特定時刻下,某技術、設備或科學領域所達到的最高發展水平或最高級狀態)的Diffusion Model(擴散模型),改良了過去「一步到位」的生成方式,把生成的過程拆成了若干個小step,並且在每一個步驟的運算中,並不直接採用模型運算出來的結果,而是在該結果的「附近」具有隨機性地選擇另一個結果。不論是實驗數據或是肉眼可見的結果,皆表明此改良取得躍升性突破。不僅是影像生成模型,大語言模型中也有類似的設計。
生成出來的結果是一個「潛空間」(Latent Space)的「向量」(可以理解成座標)。在「附近」隨機選擇另一個座標,則為從原本的座標以高斯機率分布「擴散」出去,離原本結果越近機率越高,越遠越小,這個步驟就是所謂的「加雜訊」,也就是「擴散模型」的命名由來。
在stable diffution或是midjourney生成過程的視覺化中,多半是以「降噪」的方式呈現,然而真正讓AI有可能可以往「創造力」討論的演算邏輯,其實「加入雜訊」的這個步驟,這也是生成式AI「為甚麼」且「必須」每次生成結果不一樣的主要原因。可以把這個步驟,想像成AI在一步一步的生成step中,在潛空間裡的漫步與探索。
本作品由三組裝置組成:道爾頓板、AI影像生成演算法、側面描繪儀(Physionotrace)。
![]()
![]()
![]()
![]() 道爾頓板動力裝置,產生常態分布
道爾頓板動力裝置,產生常態分布
The work begins with a Galton board, which generates a Gaussian distribution—a type of random distribution originating from real-world physical behavior. This naturally occurring randomness is then used to calculate the Gaussian noise required in the iterative process of an AI image generation model (Diffusion Model). The model follows this data to navigate through latent space, producing half-length profile portraits.
作品首先透過道爾頓板,產生來自真實物理行為的高斯分布(Gaussian Distribution,也就是常態分布)——這是一種源自現實世界的隨機分布。並依此計算出AI影像生成模型(Diffusion Model)在生成的疊代過程中所需的高斯雜訊,引導AI在潛空間(Latent Space)中進行探索,生成半身側面剪影的肖像畫。
![]()
![]()
生成半身側面剪影的肖像畫
These AI-generated portraits are displayed through a modified Physionotrace, a device originally invented in the late 18th century to trace human silhouettes. In this work, the tracing paper is replaced by an LCD screen stripped of its backlight and polarizing film, while the traditional light source for casting shadows is replaced by the screen’s backlight—a connection to the virtual world. The tracing hand is no longer human but mechanical, using a linkage mechanism to reproduce the AI-generated portraits onto real paper. Each day, the machine draws eight profile silhouettes, moving gradually from chaos to clarity.
這些AI生成的肖像,顯示在一台改造的側面描繪儀上。側面描繪儀原為18世紀末用來描繪人像輪廓的裝置,我們將描圖紙替換成移除了背光板與偏光膜的液晶螢幕,並把傳統用來打出剪影的光源,替換成連結虛擬世界的「螢幕背光」。描圖的手也不再是人手,而是機械手臂,透過連桿機構,把螢幕上的AI肖像描繪到實體紙上。每天這台機器會從雜亂至清晰,依序繪製出8張側面肖像剪影。
![]()
![]()
![]()
![]()
《潛像描繪儀》繪置側面肖像剪影
By using noise derived from the physical world instead of the computer’s pseudo-random number tables traditionally used in AI, the work establishes a link between the virtual latent space in which AI operates and the tangible physical world humans inhabit. It extends the historical significance of the Physionotrace—a device that once marked the shift from artistic subjectivity to mechanical precision and standardization—into the contemporary revolution of AI-generated imagery, where the act of depiction evolves from representing the visible world to recomposing the virtual one through algorithmic computation.
這件作品試圖用「來自真實世界的雜訊」來取代傳統AI所使用的電腦亂數表,讓AI所運作的虛擬潛空間,能與人類所處的物理世界建立起某種連結。並將18世紀末側面描繪儀代表的歷史意義——見證影像從藝術家的主觀詮釋,邁向「準確化、標準化」的機器觀看方式的影像革命,進一步延伸至AI生成影像從可見世界的描摹到虛擬世界重組演算的再次革命。
![]()
![]()
![]()
![]()
每天描繪儀會從雜亂至清晰,依序繪製出8張側面肖像剪影。
![]()
![]()
![]()
Special Thanks
Lin & Lin Gallery
Taipei Fine Arts Museum
Installation Design and Production
Huang Hao-Min
Technical Support
Lai Yin-Hsiang
Exhibition Diagram Design
Chou Fang-Yu
Technical consultant
Chen Shanboy
特別感謝
大未來林舍畫廊
台北市立美術館
裝置設計製作
黃浩旻
技術協力
賴英翔
展覽圖形設計
周芳伃
技術顧問
陳宣伯
Mechanical Installation, Generative AI Algorithms, Real-Time Animation, Mixed Media
Dimensions Variable
2025
潛像描繪儀
機械裝置、機器繪圖、演算法、生成動畫、複合媒材
依場地而定
2025
︎ Magic Noise: How AI Wanders in the Latent Space, LIN & LIN Gallery
︎ 神奇的雜訊:AI的潛在漫步方式,大未來林舍畫廊

展場入口處為《潛像描繪儀》畫出的肖像畫
In recent years, the Diffusion Model has become the state of the art (SOTA) in image generation systems. It improves upon earlier “one-step” generative methods by dividing the process into a series of smaller steps. At each step, instead of directly using the model’s computed output, the algorithm randomly selects a nearby result within a certain range. Both experimental data and visual outcomes demonstrate that this modification has brought about a major breakthrough. A similar design principle is also found in large language models.
The generated output exists as a vector in latent space—essentially, a coordinate. Randomly selecting another coordinate nearby corresponds to diffusing outward from the original point with a Gaussian probability distribution: the closer a point is, the higher its probability; the farther it is, the lower. This process, known as adding noise, gives the diffusion model its name.
In visualizations of models like Stable Diffusion or Midjourney, the process is often represented as “denoising.” However, the true logic that allows AI to approach something resembling creativity lies precisely in the step of adding noise. This is the main reason—and necessity—behind why generative AI produces different results each time. One can imagine this process as AI taking a wandering exploration through latent space, step by step, during its generative journey.
This work consists of three installations: a Galton board, an AI image generation algorithm, and a Physionotrace.
近幾年成為影像生成模型SOTA(State of The Art,意指某特定時刻下,某技術、設備或科學領域所達到的最高發展水平或最高級狀態)的Diffusion Model(擴散模型),改良了過去「一步到位」的生成方式,把生成的過程拆成了若干個小step,並且在每一個步驟的運算中,並不直接採用模型運算出來的結果,而是在該結果的「附近」具有隨機性地選擇另一個結果。不論是實驗數據或是肉眼可見的結果,皆表明此改良取得躍升性突破。不僅是影像生成模型,大語言模型中也有類似的設計。
生成出來的結果是一個「潛空間」(Latent Space)的「向量」(可以理解成座標)。在「附近」隨機選擇另一個座標,則為從原本的座標以高斯機率分布「擴散」出去,離原本結果越近機率越高,越遠越小,這個步驟就是所謂的「加雜訊」,也就是「擴散模型」的命名由來。
在stable diffution或是midjourney生成過程的視覺化中,多半是以「降噪」的方式呈現,然而真正讓AI有可能可以往「創造力」討論的演算邏輯,其實「加入雜訊」的這個步驟,這也是生成式AI「為甚麼」且「必須」每次生成結果不一樣的主要原因。可以把這個步驟,想像成AI在一步一步的生成step中,在潛空間裡的漫步與探索。
本作品由三組裝置組成:道爾頓板、AI影像生成演算法、側面描繪儀(Physionotrace)。



 道爾頓板動力裝置,產生常態分布
道爾頓板動力裝置,產生常態分布The work begins with a Galton board, which generates a Gaussian distribution—a type of random distribution originating from real-world physical behavior. This naturally occurring randomness is then used to calculate the Gaussian noise required in the iterative process of an AI image generation model (Diffusion Model). The model follows this data to navigate through latent space, producing half-length profile portraits.
作品首先透過道爾頓板,產生來自真實物理行為的高斯分布(Gaussian Distribution,也就是常態分布)——這是一種源自現實世界的隨機分布。並依此計算出AI影像生成模型(Diffusion Model)在生成的疊代過程中所需的高斯雜訊,引導AI在潛空間(Latent Space)中進行探索,生成半身側面剪影的肖像畫。


生成半身側面剪影的肖像畫
These AI-generated portraits are displayed through a modified Physionotrace, a device originally invented in the late 18th century to trace human silhouettes. In this work, the tracing paper is replaced by an LCD screen stripped of its backlight and polarizing film, while the traditional light source for casting shadows is replaced by the screen’s backlight—a connection to the virtual world. The tracing hand is no longer human but mechanical, using a linkage mechanism to reproduce the AI-generated portraits onto real paper. Each day, the machine draws eight profile silhouettes, moving gradually from chaos to clarity.
這些AI生成的肖像,顯示在一台改造的側面描繪儀上。側面描繪儀原為18世紀末用來描繪人像輪廓的裝置,我們將描圖紙替換成移除了背光板與偏光膜的液晶螢幕,並把傳統用來打出剪影的光源,替換成連結虛擬世界的「螢幕背光」。描圖的手也不再是人手,而是機械手臂,透過連桿機構,把螢幕上的AI肖像描繪到實體紙上。每天這台機器會從雜亂至清晰,依序繪製出8張側面肖像剪影。




《潛像描繪儀》繪置側面肖像剪影
By using noise derived from the physical world instead of the computer’s pseudo-random number tables traditionally used in AI, the work establishes a link between the virtual latent space in which AI operates and the tangible physical world humans inhabit. It extends the historical significance of the Physionotrace—a device that once marked the shift from artistic subjectivity to mechanical precision and standardization—into the contemporary revolution of AI-generated imagery, where the act of depiction evolves from representing the visible world to recomposing the virtual one through algorithmic computation.
這件作品試圖用「來自真實世界的雜訊」來取代傳統AI所使用的電腦亂數表,讓AI所運作的虛擬潛空間,能與人類所處的物理世界建立起某種連結。並將18世紀末側面描繪儀代表的歷史意義——見證影像從藝術家的主觀詮釋,邁向「準確化、標準化」的機器觀看方式的影像革命,進一步延伸至AI生成影像從可見世界的描摹到虛擬世界重組演算的再次革命。




每天描繪儀會從雜亂至清晰,依序繪製出8張側面肖像剪影。



Special Thanks
Lin & Lin Gallery
Taipei Fine Arts Museum
Installation Design and Production
Huang Hao-Min
Technical Support
Lai Yin-Hsiang
Exhibition Diagram Design
Chou Fang-Yu
Technical consultant
Chen Shanboy
特別感謝
大未來林舍畫廊
台北市立美術館
裝置設計製作
黃浩旻
技術協力
賴英翔
展覽圖形設計
周芳伃
技術顧問
陳宣伯
Residual Noise
Technical pen and silkscreen
38 x 38 cm
2025
噪聲殘影
針筆、絹板
38 x 38 cm
2025
︎ Magic Noise: How AI Wanders in the Latent Space, LIN & LIN Gallery
︎ 神奇的雜訊:AI的潛在漫步方式,大未來林舍畫廊
![]()
《 噪聲殘影 》 樹系列
The work employs a method called “Vibe Coding” to generate prompts for AI, producing programs capable of drawing fractal patterns found in nature—such as branches and snowflakes. Using the same drawing rules, the artist first hand-renders the patterns in black lines on paper, then applies silkscreen printing to overlay the AI-generated version in white lines atop the hand-drawn image.
Because the computer’s precise white lines cannot perfectly cover the subtle irregularities of the hand-drawn black ones, traces of disorder remain visible. Through this subtractive process—between manual drawing and silkscreen overlay—the artist “calculates” the imperfections of human gesture, using these residual, chaotic lines to reflect on the abstract meaning of “noise” introduced by generative AI as it wanders through latent space.
本作品透過氛圍編碼(Vibe Coding)給AI提示詞的方式,生成可以繪製大自然中的碎形圖案——樹枝、雪花的程式。接著使用相同的繪製規則,手工以黑色線條畫在圖紙上,再以絹板印刷的方式,將電腦繪製的圖案以白色線條覆蓋在手繪的黑色線條上。電腦精準繪製的白色線條無法覆蓋具有手繪誤差的黑色線條,因而留下隱約可見的雜亂線條。藝術家藉由手繪與絹板的「減法」過程,「計算」人為的不精確性,並透過這些留下的雜亂線條,試圖回應生成式AI在潛空間探索時,加入「雜訊」所蘊含的抽象意義。
![]()
![]()
《噪聲殘影》樹系列,展場紀錄
![]()
《噪聲殘影》雪花系列,展場紀錄
![]()
![]()
《噪聲殘影》雪花系列,展場紀錄
Process Details
1. Image Generation: Using a large language model with a Vibe Coding approach, the artist generates programs capable of drawing natural fractal geometries such as tree branches and snowflakes.
2. Code Translation: The generated program is then translated into human-readable rules and steps, including precise parameters such as branching angles, length ratios, and positional relationships.
3. Custom Drawing Tools: Special triangular rulers with specific angles and lengths are custom-made.
4. Drawing: Following the translated rules and steps, the artist draws with technical pens of constant line width, minimizing human error as much as possible.
5. Screen Preparation: The AI-generated image is printed via inkjet and exposed to produce a silkscreen stencil.
6. Registration and Printing: The first hand-drawn stroke serves as the reference point for alignment, and the silkscreen image is printed precisely over the drawing.
詳細步驟
1. 生成影像: 透過大型語言模型,使用氛圍編碼的方式,生成可以繪製大自然中的碎形幾何圖案——樹枝、雪花的程式。
2. 轉譯程式碼 : 將該程式轉譯成人類可閱讀的規則與步驟,包含詳細的分支角度、長度比例、位置等等。
3. 訂製繪圖工具 : 訂製特殊角度與長度的三角板。
4. 繪製 : 依照轉譯後規則與步驟,使用粗細不會有變化的針管筆繪製,盡可能地減少誤差。
5. 製版 : 將程式生成的影像透過噴墨、曝光,製作絲絹網板。
6.對位與印刷 : 以繪製的第一個筆劃作為原點對位,並進行絹板印刷。
Special Thanks
Lin & Lin Gallery
Siyat Moses — Silkscreen Production
特別感謝
大未來林舍畫廊
阮原閩 版畫絹印製作
Technical pen and silkscreen
38 x 38 cm
2025
噪聲殘影
針筆、絹板
38 x 38 cm
2025
︎ Magic Noise: How AI Wanders in the Latent Space, LIN & LIN Gallery
︎ 神奇的雜訊:AI的潛在漫步方式,大未來林舍畫廊

《 噪聲殘影 》 樹系列
The work employs a method called “Vibe Coding” to generate prompts for AI, producing programs capable of drawing fractal patterns found in nature—such as branches and snowflakes. Using the same drawing rules, the artist first hand-renders the patterns in black lines on paper, then applies silkscreen printing to overlay the AI-generated version in white lines atop the hand-drawn image.
Because the computer’s precise white lines cannot perfectly cover the subtle irregularities of the hand-drawn black ones, traces of disorder remain visible. Through this subtractive process—between manual drawing and silkscreen overlay—the artist “calculates” the imperfections of human gesture, using these residual, chaotic lines to reflect on the abstract meaning of “noise” introduced by generative AI as it wanders through latent space.
本作品透過氛圍編碼(Vibe Coding)給AI提示詞的方式,生成可以繪製大自然中的碎形圖案——樹枝、雪花的程式。接著使用相同的繪製規則,手工以黑色線條畫在圖紙上,再以絹板印刷的方式,將電腦繪製的圖案以白色線條覆蓋在手繪的黑色線條上。電腦精準繪製的白色線條無法覆蓋具有手繪誤差的黑色線條,因而留下隱約可見的雜亂線條。藝術家藉由手繪與絹板的「減法」過程,「計算」人為的不精確性,並透過這些留下的雜亂線條,試圖回應生成式AI在潛空間探索時,加入「雜訊」所蘊含的抽象意義。


《噪聲殘影》樹系列,展場紀錄

《噪聲殘影》雪花系列,展場紀錄


《噪聲殘影》雪花系列,展場紀錄
Process Details
1. Image Generation: Using a large language model with a Vibe Coding approach, the artist generates programs capable of drawing natural fractal geometries such as tree branches and snowflakes.
2. Code Translation: The generated program is then translated into human-readable rules and steps, including precise parameters such as branching angles, length ratios, and positional relationships.
3. Custom Drawing Tools: Special triangular rulers with specific angles and lengths are custom-made.
4. Drawing: Following the translated rules and steps, the artist draws with technical pens of constant line width, minimizing human error as much as possible.
5. Screen Preparation: The AI-generated image is printed via inkjet and exposed to produce a silkscreen stencil.
6. Registration and Printing: The first hand-drawn stroke serves as the reference point for alignment, and the silkscreen image is printed precisely over the drawing.
詳細步驟
1. 生成影像: 透過大型語言模型,使用氛圍編碼的方式,生成可以繪製大自然中的碎形幾何圖案——樹枝、雪花的程式。
2. 轉譯程式碼 : 將該程式轉譯成人類可閱讀的規則與步驟,包含詳細的分支角度、長度比例、位置等等。
3. 訂製繪圖工具 : 訂製特殊角度與長度的三角板。
4. 繪製 : 依照轉譯後規則與步驟,使用粗細不會有變化的針管筆繪製,盡可能地減少誤差。
5. 製版 : 將程式生成的影像透過噴墨、曝光,製作絲絹網板。
6.對位與印刷 : 以繪製的第一個筆劃作為原點對位,並進行絹板印刷。
Special Thanks
Lin & Lin Gallery
Siyat Moses — Silkscreen Production
特別感謝
大未來林舍畫廊
阮原閩 版畫絹印製作
Folded Spacetime
Custom-designed star projection device
Dimension Variable
2025
尺寸依照空間而定
2025
![]()
《時空摺面》展場紀錄,星空投影在牆面轉角處
![]()
![]()
《時空摺面》展場紀錄,自製星空投影裝置
Humans perceive depth through the parallax created by the distance between our two eyes. Yet when our gaze reaches astronomical scales, the distance between our eyes becomes negligible. The starry sky thus appears almost entirely flat—countless stars separated by unimaginable distances collapse into adjacent points projected onto the retina.
The artist projects a star-field onto wall surfaces set at different angles. As the stars move at a constant speed across the projection, their apparent motion sharply changes when crossing the corner, creating a perceptual distortion. Through this visual fold, the work imagines and responds to humanity’s compressed, sliced understanding of the vast scales of the universe.
人類藉由雙眼之間的距離所產生的的像差而得到立體視覺,當觀看的目標遙遠至宇宙尺度時,雙眼之間的距離顯得微乎其微,幾乎可以忽略不計。於是,人眼對於星空的視覺幾乎是完全平面的,即便這些點點繁星之間,存在著人類窮極一生都無法跨越的距離,在我們眼裡,仍然僅是投影在視網膜上的鄰近小點。
藝術家在把星空影像投影在不同角度的平面上,使等速運轉的天體的在視覺上產生速度變化,試圖以此來想像與回應人類對於浩瀚尺度宇宙的切片、壓縮的認知狀態。
![]()
《時空摺面》展場紀錄
Custom-designed star projection device
Dimension Variable
2025
時空摺面
自製星空投影裝置尺寸依照空間而定
2025

《時空摺面》展場紀錄,星空投影在牆面轉角處


《時空摺面》展場紀錄,自製星空投影裝置
Humans perceive depth through the parallax created by the distance between our two eyes. Yet when our gaze reaches astronomical scales, the distance between our eyes becomes negligible. The starry sky thus appears almost entirely flat—countless stars separated by unimaginable distances collapse into adjacent points projected onto the retina.
The artist projects a star-field onto wall surfaces set at different angles. As the stars move at a constant speed across the projection, their apparent motion sharply changes when crossing the corner, creating a perceptual distortion. Through this visual fold, the work imagines and responds to humanity’s compressed, sliced understanding of the vast scales of the universe.
人類藉由雙眼之間的距離所產生的的像差而得到立體視覺,當觀看的目標遙遠至宇宙尺度時,雙眼之間的距離顯得微乎其微,幾乎可以忽略不計。於是,人眼對於星空的視覺幾乎是完全平面的,即便這些點點繁星之間,存在著人類窮極一生都無法跨越的距離,在我們眼裡,仍然僅是投影在視網膜上的鄰近小點。
藝術家在把星空影像投影在不同角度的平面上,使等速運轉的天體的在視覺上產生速度變化,試圖以此來想像與回應人類對於浩瀚尺度宇宙的切片、壓縮的認知狀態。

《時空摺面》展場紀錄
False Color Photo Booth
Photo booth、Mixed media
Dimension Variable
2025
假色拍貼機
拍貼機、複合媒材
尺寸依空間而定
2025
![]()
《假色拍貼機》觀眾繪製完成的假色自拍照
![]()
![]()
《假色拍貼機》展場紀錄,右側為拍照區,左側為上色區
Conventional cameras—whether film or digital—are designed to reproduce human vision. Their sensitivity range, RGB filters, and white-balance settings are all aimed at faithfully restoring what our eyes perceive.
Astronomical photography, however, has a different goal: to record as much specific information as possible, including light from wavelengths invisible to the human eye. Many of the dazzling images of celestial objects that we admire are in fact composites of such invisible light, later assigned “false colors” to reveal hidden details.
This installation invites you to create your own false-color self-portrait.
Step into the photo booth and receive a “photograph” represented as a matrix of numbers. With the colored crayons provided, match color intensity to the numerical values and fill in the grid. The result is a one-of-a-kind, hand-crafted false-color selfie.
一般照相機不論是底片相機或是數位相機,感光範圍、RGB濾鏡、白平衡等等的設計目標都是為了再現、還原人眼視覺,然而對於天文攝影來說,目標則是可以記錄下更多、更特定的資訊,這些資訊中包含了很多人眼看不見的波長的光。而我們看到的燦爛的天體照片,其實很多都是由這些不可見光,再套上假色所組合而成。
讓我們試著自己畫一張假色自拍照吧!
觀眾使用拍貼機,將會獲得一張由一堆數字矩陣排列的「照片」,並且可以使用現場提供的各個不同顏色的蠟筆,依據顏色深淺對應到數字大小塗色,獲得一張獨一無二的手工假色自拍照!
![]()
![]()
《假色拍貼機》 , 2049媽祖遶月太空站,晶創人文計畫總辦提供 , 攝影:簡豪江
![]()
《假色拍貼機》上色提示,數字越小塗越淺的顏色,數字越大塗越深的顏色
![]()
![]()
《假色拍貼機》拍攝裝置,點擊螢幕即可開始自拍
![]()
![]()
《假色拍貼機》觀眾完成的假色自拍照
![]()
![]()
《假色拍貼機》上色區,選一種顏色,依照數字大小對應顏色深淺上色
裝置設計製作: 黃浩旻
Photo booth、Mixed media
Dimension Variable
2025
假色拍貼機
拍貼機、複合媒材
尺寸依空間而定
2025

《假色拍貼機》觀眾繪製完成的假色自拍照


《假色拍貼機》展場紀錄,右側為拍照區,左側為上色區
Conventional cameras—whether film or digital—are designed to reproduce human vision. Their sensitivity range, RGB filters, and white-balance settings are all aimed at faithfully restoring what our eyes perceive.
Astronomical photography, however, has a different goal: to record as much specific information as possible, including light from wavelengths invisible to the human eye. Many of the dazzling images of celestial objects that we admire are in fact composites of such invisible light, later assigned “false colors” to reveal hidden details.
This installation invites you to create your own false-color self-portrait.
Step into the photo booth and receive a “photograph” represented as a matrix of numbers. With the colored crayons provided, match color intensity to the numerical values and fill in the grid. The result is a one-of-a-kind, hand-crafted false-color selfie.
一般照相機不論是底片相機或是數位相機,感光範圍、RGB濾鏡、白平衡等等的設計目標都是為了再現、還原人眼視覺,然而對於天文攝影來說,目標則是可以記錄下更多、更特定的資訊,這些資訊中包含了很多人眼看不見的波長的光。而我們看到的燦爛的天體照片,其實很多都是由這些不可見光,再套上假色所組合而成。
讓我們試著自己畫一張假色自拍照吧!
觀眾使用拍貼機,將會獲得一張由一堆數字矩陣排列的「照片」,並且可以使用現場提供的各個不同顏色的蠟筆,依據顏色深淺對應到數字大小塗色,獲得一張獨一無二的手工假色自拍照!


《假色拍貼機》 , 2049媽祖遶月太空站,晶創人文計畫總辦提供 , 攝影:簡豪江



《假色拍貼機》拍攝裝置,點擊螢幕即可開始自拍


《假色拍貼機》觀眾完成的假色自拍照


《假色拍貼機》上色區,選一種顏色,依照數字大小對應顏色深淺上色
裝置設計製作: 黃浩旻
Prompt: Dupe arts
Mixed media、Video
118x78cm、6’39”
2024
Prompt: Dupe arts
複合媒材、錄像
118x78cm、6’39”
2024
Collaborator : Shanboy CHEN
![]()
![]()
《Prompt: Dupe arts》,未來媒體藝術節,臺灣當代文化實驗場提供,攝影:三月影像 許博彥
The term "Dupe" in Dupe Arts reflects the rise of Dupe Culture that has emerged alongside the booming development of social media and e-commerce platforms in China, with a significant following in the West as well. This culture revolves around the pursuit of lower-priced alternatives that resemble high-end products in quality and style, promoting rational consumption and creativity. It is more than just a trend; it's a lifestyle choice that values resourcefulness over luxury. Unlike counterfeits, dupes do not mimic original trademarks but offer legal alternatives with similar design and functionality, which can even increase consumer desire for the original products by expanding their visibility.
Following this philosophy, Dupe Arts is not about copying or mechanical reproduction, like a replica painting, but rather imitation of existing artworks, capturing their essence in a more accessible form. The psychological motivation behind Dupe Arts is both a critique of high art and an aspiration towards it, suggesting potential for broader dissemination. Similarly, image-generating AI operates on a parallel logic by producing visually compelling works at a lower cost through complex imitation and recombination of existing images. In this context, exploring prompts and datasets becomes a new avenue for creativity.
For many, the demand for art may not hinge on originality. However, for creators, originality remains a crucial marker of artistic agency. How does the art market assign value? What impact will AI-generated art have as a dupe tool? How should creators respond?
We searched "Dupe Arts" on Youtube and saw that Youtubers were teaching a simple and affordable way to draw abstract paintings that looked like those in expensive galleries. We draw according to the steps, and then take photos of the finished works and feed them to the generative AI, which generates a large number of similar abstract paintings.
Dupe Arts 中的 Dupe 指的是近幾年隨中國的自媒體、電商平台蓬勃發展所興起的「平替文化」(平價替代品),在歐美亦蔚為風潮。指尋找價格較低但品質和款式跟高價產品相似的替代品的消費現象,並認為尋找的過程可以激發創意和探索。平替文化不僅是省錢的消費現象,更是一種理性消費的生活態度體現。平替品並非仿冒原商品,而是一種相對合法的替代方案,亦可以提升消費者對原商品的嚮往。
承襲於此,Dupe Arts 並非抄襲,也不是如複製畫的機械複製,而更像是對於現成物的「模仿」,透過平價的方式創作出風格接近的作品。Dupe Arts 的心理動機既是對高貴藝術品的反動,同時也是嚮往,更是一種擴散的可能。圖像生成AI 也存在類似邏輯,以低廉的成本對資料集中的現成圖像,進行「複雜的模仿與重組」。為了生成出更滿意的圖像,對於提示詞與資料集的現成圖像的探索,亦成為一種新的創意可能。
從 Dupe Arts 或是圖像生成 AI 來看,對也許為數不少的人來說,他們對藝術的「需求」並不是原創性,然而對身為藝術「供給」者的創作者來說,原創性又是創作者的「能動性」的重要證據。藝術是如何被賦予價值?圖像生成 AI 作為一種平替工具又會產生什麼影響?身為創作者的我們又該如何面對?
我們在Youtube搜尋「Dupe Arts」,看到Youtuber在教學以簡單又平價的方式,畫出如同昂貴畫廊的抽象繪畫作品。我們照著步驟畫出,再將畫好後的作品翻拍成照片給生成式AI,生成出大量相似的抽象繪畫作品。
![]()
![]()
![]()
![]()
《Prompt: Dupe arts》錄像截圖,照著Youtuber的Dupe arts教學畫出抽象作品
![]()
《Prompt: Dupe arts》錄像截圖,用Stable Diffusion生成出大量類似的抽象圖樣
![]()
《Prompt: Dupe arts》,未來媒體藝術節,臺灣當代文化實驗場提供,攝影:三月影像 許博彥
Open Source Software Used:
stable-diffusion-webui AGPL-3.0 license
ControllNet Apache-2.0 license
stable-diffusion-v1-5/stable-diffusion-v1-5 CreativeML Open RAIL-M
Youtube Video Source:
Dupe for $4,300 Artwork! + Home Decor Updates! RAVEN ELYSE DIY
Gaffer:
Itami Liang
燈光指導:
梁敦學
Mixed media、Video
118x78cm、6’39”
2024
Prompt: Dupe arts
複合媒材、錄像
118x78cm、6’39”
2024
Collaborator : Shanboy CHEN
共同創作者:陳宣伯


《Prompt: Dupe arts》,未來媒體藝術節,臺灣當代文化實驗場提供,攝影:三月影像 許博彥
The term "Dupe" in Dupe Arts reflects the rise of Dupe Culture that has emerged alongside the booming development of social media and e-commerce platforms in China, with a significant following in the West as well. This culture revolves around the pursuit of lower-priced alternatives that resemble high-end products in quality and style, promoting rational consumption and creativity. It is more than just a trend; it's a lifestyle choice that values resourcefulness over luxury. Unlike counterfeits, dupes do not mimic original trademarks but offer legal alternatives with similar design and functionality, which can even increase consumer desire for the original products by expanding their visibility.
Following this philosophy, Dupe Arts is not about copying or mechanical reproduction, like a replica painting, but rather imitation of existing artworks, capturing their essence in a more accessible form. The psychological motivation behind Dupe Arts is both a critique of high art and an aspiration towards it, suggesting potential for broader dissemination. Similarly, image-generating AI operates on a parallel logic by producing visually compelling works at a lower cost through complex imitation and recombination of existing images. In this context, exploring prompts and datasets becomes a new avenue for creativity.
For many, the demand for art may not hinge on originality. However, for creators, originality remains a crucial marker of artistic agency. How does the art market assign value? What impact will AI-generated art have as a dupe tool? How should creators respond?
We searched "Dupe Arts" on Youtube and saw that Youtubers were teaching a simple and affordable way to draw abstract paintings that looked like those in expensive galleries. We draw according to the steps, and then take photos of the finished works and feed them to the generative AI, which generates a large number of similar abstract paintings.
Dupe Arts 中的 Dupe 指的是近幾年隨中國的自媒體、電商平台蓬勃發展所興起的「平替文化」(平價替代品),在歐美亦蔚為風潮。指尋找價格較低但品質和款式跟高價產品相似的替代品的消費現象,並認為尋找的過程可以激發創意和探索。平替文化不僅是省錢的消費現象,更是一種理性消費的生活態度體現。平替品並非仿冒原商品,而是一種相對合法的替代方案,亦可以提升消費者對原商品的嚮往。
承襲於此,Dupe Arts 並非抄襲,也不是如複製畫的機械複製,而更像是對於現成物的「模仿」,透過平價的方式創作出風格接近的作品。Dupe Arts 的心理動機既是對高貴藝術品的反動,同時也是嚮往,更是一種擴散的可能。圖像生成AI 也存在類似邏輯,以低廉的成本對資料集中的現成圖像,進行「複雜的模仿與重組」。為了生成出更滿意的圖像,對於提示詞與資料集的現成圖像的探索,亦成為一種新的創意可能。
從 Dupe Arts 或是圖像生成 AI 來看,對也許為數不少的人來說,他們對藝術的「需求」並不是原創性,然而對身為藝術「供給」者的創作者來說,原創性又是創作者的「能動性」的重要證據。藝術是如何被賦予價值?圖像生成 AI 作為一種平替工具又會產生什麼影響?身為創作者的我們又該如何面對?
我們在Youtube搜尋「Dupe Arts」,看到Youtuber在教學以簡單又平價的方式,畫出如同昂貴畫廊的抽象繪畫作品。我們照著步驟畫出,再將畫好後的作品翻拍成照片給生成式AI,生成出大量相似的抽象繪畫作品。




《Prompt: Dupe arts》錄像截圖,照著Youtuber的Dupe arts教學畫出抽象作品
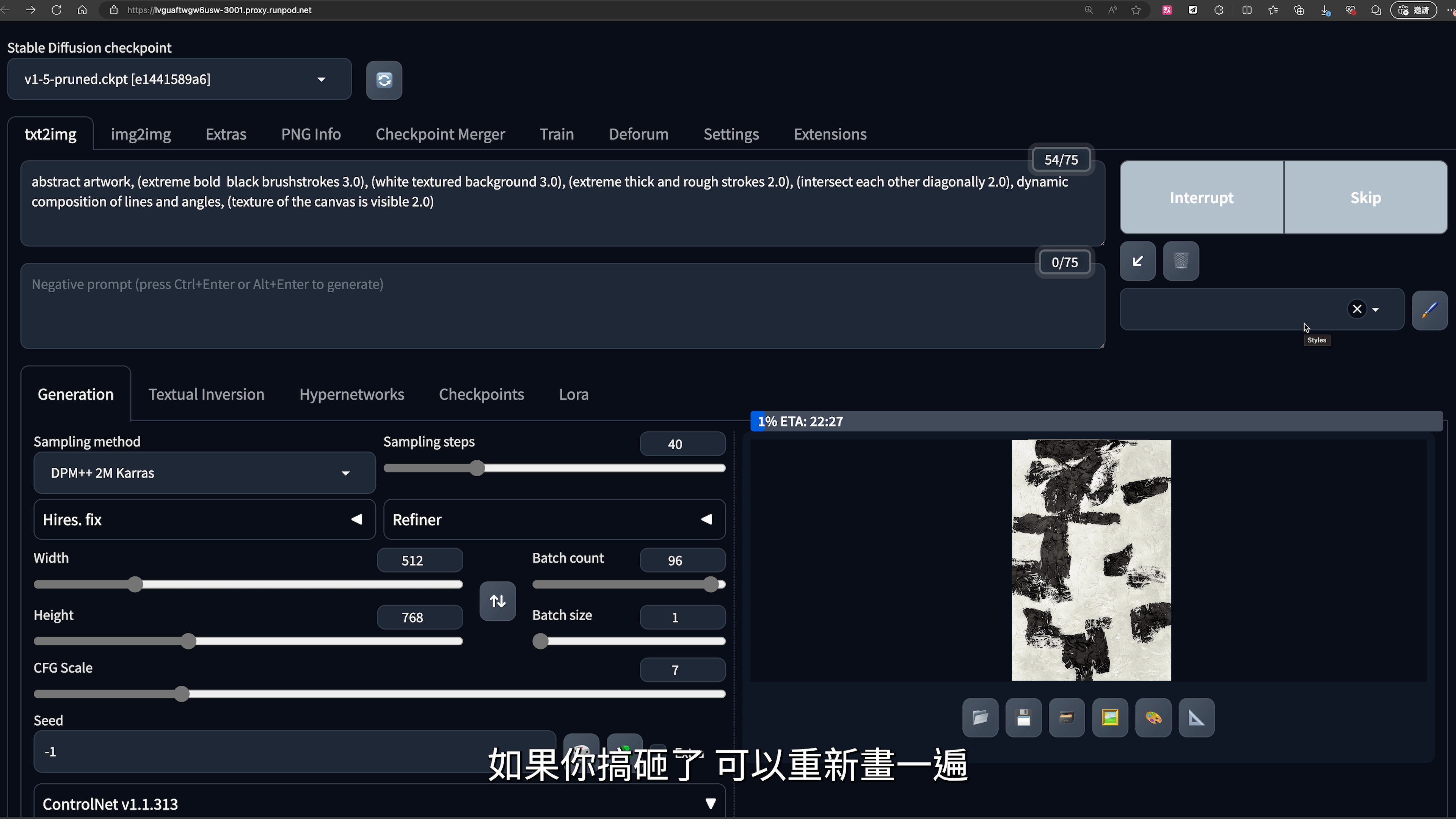
《Prompt: Dupe arts》錄像截圖,用Stable Diffusion生成出大量類似的抽象圖樣

《Prompt: Dupe arts》,未來媒體藝術節,臺灣當代文化實驗場提供,攝影:三月影像 許博彥
Open Source Software Used:
stable-diffusion-webui AGPL-3.0 license
ControllNet Apache-2.0 license
stable-diffusion-v1-5/stable-diffusion-v1-5 CreativeML Open RAIL-M
Youtube Video Source:
Dupe for $4,300 Artwork! + Home Decor Updates! RAVEN ELYSE DIY
Gaffer:
Itami Liang
燈光指導:
梁敦學